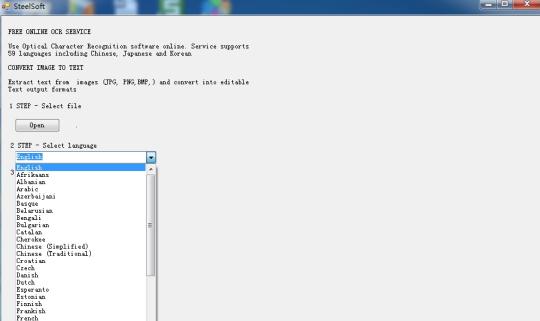
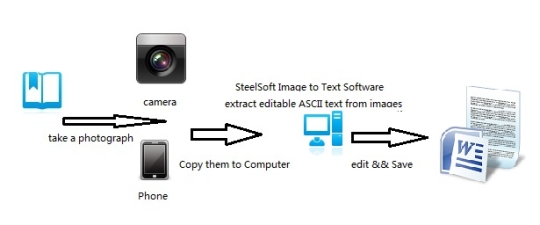
Công nhận văn bản từ hình ảnh bằng cách sử dụng động cơ Tesseract OCR dựa trên công nghệ điện toán đám mây.
Sử dụng phần mềm Optical Character Recognition trực tuyến. Dịch vụ hỗ trợ 59 ngôn ngữ bao gồm Trung Quốc, Nhật Bản và Hàn Quốc. Trích xuất văn bản từ hình ảnh (JPG, PNG, BMP, TIF) và chuyển đổi sang định dạng đầu ra văn bản có thể chỉnh sửa.
Nó được dựa trên công nghệ điện toán đám mây, và động cơ rất nổi tiếng OCR (OCR Tesseract Engine), như vậy chỉ có hàng trăm KB, nhưng nó có thể trích xuất văn bản trong 59 ngôn ngữ, từ các hình ảnh.
Nó hỗ trợ nhiều ngôn ngữ hơn: Bungari, Catalan, Cộng hòa Séc, Đan Mạch, Hà Lan, Anh, Phần Lan, Pháp, Đức, Hy Lạp, Hungary, Indonesia, Ý, Latvia, Litva, Na Uy, Ba Lan, Bồ Đào Nha, Rumani, Nga, Serbian, Slovak, tiếng Slovenia , Tây Ban Nha, Thụy Điển, Tagalog, Thổ Nhĩ Kỳ, tiếng Ukraina, tiếng Việt vv
là gì mới trong phiên bản này:..
Phiên bản 5.0 bao gồm UE cải tiến

Bình luận không